One of the things Linux users nearly always complain about is audio. From it flat-out not working, to it not getting picked up in screen shares, it always seems to be behind most of the issues that users cite with any distro (that and NVIDIA drivers but I digress). Fortunately in recent years, the audio situation has gotten a ton better with the introduction of PipeWire.
PipeWire, a Crash Course
PipeWire, to put it simply, is an audio-visual processing+routing tool
that allows different streams of content to be “wired” and processed
in various ways to reach a target destination. It itself sits on top
of various audio and video backends and acts as a common interface
that can be interacted with via a set of programs
provided by the project, config files, or libpipewire, a wrapper around
the PipeWire socket itself. Each of these methods have their advantages:
with the programs, you can take the high-level tools given to you to
interface with PipeWire and get pretty far without having
to delve deep into the internals of media routing. Although
this is arguably the simplest to get started with, it does relegate
you to more “script-like” approaches of interacting with the audio
server and incurs the overhead of launching a program every time
you need to do something. Config files, as their names imply, give
the user the capability to configure the audio server and filtering
chain itself at startup. This approach works extremely well
when users want a static approach to their configuration but do fall
short when more complex runtime processing is required. The final
interaction method, libpipewire, is the most complex but flexible
way to interact with PipeWire and gives a large amount of control
to the developer.
Although this gives a high-level overview of what PipeWire is and how we interact with it, we need to be a little more familiar with it before we start doing anything with it.
The Node Graph
Long explanations are all well and good but this is a case where a picture can speak a thousand words. Using the excellent tool Helvum (or qpwgraph), users can view (and edit!) their own node graphs for their system:
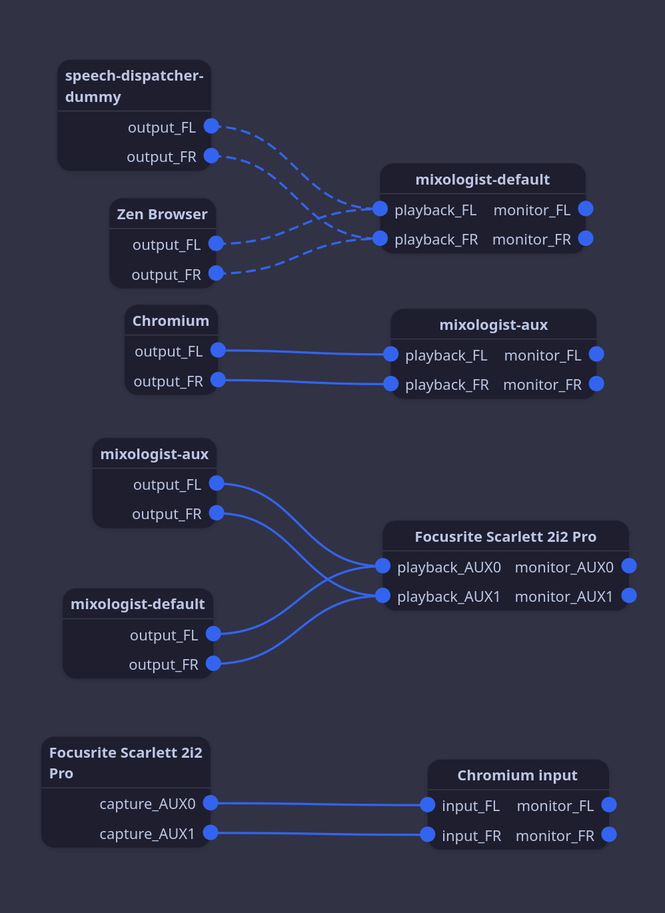
So what do these fancy boxes and lines mean? Well, each of these
boxes represents a node in the graph and each line represents
a link. Nodes represent things that either emit, consume, or
modify media and have any number of ports that input or output
data. Links act as bridges between these ports and can be viewed
as linking a display cable between your computer and your
monitor. You might also notice some nodes with mixologist in the
graph, ignore those for now, they’re a surprise for later.
Loopback
Loopback in PipeWire-land is a simple, yet powerful tool to give
users more control over their streams. In short, they take media
from an input and forward it to an output, allowing users to
create virtual devices and modify the data going through them
as they see fit. There is a module provided to us to use that
packages up all that logic inside and allows us to treat loopback
modules as if they were any other node in the graph. Although
there is a provided tool to create loopback devices via the
command line (pw-loopback), one can also load the
libpipewire-module-loopback module via libpipewire to
interact with them via code (without having to invoke subprocesses).
libpipewire
Let’s get going in our first libpipewire application. Fortunately,
the docs are relatively good and full program examples can be
found by looking at the source code of tools like pw-cli.
Getting started is as simple as writing the following C program:
| |
Bindings
Unfortunately, I am a masochist and an Odin user (jury is still out on whether those two are linked). That means that I need to either generate or write bindings. Although generation is a valid approach, writing them by hand should give me a better idea of how the library works and make it so that I can better ensure mapping of concepts from PipeWire to Odin (which will come in handy as we will see later).
To start, we need to write the following pipewire.odin in a
pipewire/ directory:
| |
This is relatively simple, just telling the linker to link
libpipewire and giving some procedures to link with,
allowing us to write the following program (executable with
odin run .):
| |
In this case, we are safe to pass
niltopw_initas we have no arguments that we need to pass tolibpipewireitself.
The benefit to using Odin here might not yet
be apparent but in short, it will allow us to
use some nice language
features like dynamic arrays, maps, explicit allocators,
and the excellent core library.
This covers most of our bases for bindings — any time
we need a new procedure, we can simply translate the types
from C to Odin and mirror the procedures and structs on
the Odin side. There are however, a few glaring issues:
our arch-nemeses static inline and macros (why binding generators
shouldn’t be trusted to “just work” with this project).
PipeWire heavily relies on libspa, a header-only library
that extensively uses C macros in inventive ways
(i.e. implementing interfaces in C). The issue with these
procedures and macros is that they aren’t exported by
libpipewire itself and instead must be reimplemented on
the binding side. Fortunately, clangd does provide macro
expansion on hover so both static inline procedures and
macros can be trivially copied over and translated (even if some
look a bit ugly as seen here):
| |
Users of the bindings don’t have to write anything this gross.
Fortunately, most of this work is rather trivial and can
amount to a somewhat relaxing experience cranking out
code without a ton of thinking. Additionally, we don’t
necessarily need to write bindings for all of libpipewire,
just the parts of the API we will use which does tone down
the workload a fair bit.
ChatMix
What is ChatMix
Remember a couple minutes earlier when I mentioned those
mixologist nodes? Well, here’s where they come into play:
a few months ago a friend purchased a SteelSeries
headset. This headset had a feature called ChatMix, accessible through
the (half-working) Sonar software. ChatMix, in short, allows
users to create virtual audio devices and use a wheel on
the side of the headset to mix volumes between those
audio devices.
This can be extremely useful in certain cases where you may be in a long running Discord call and also have audio playing from another program (say a browser running FoundryVTT). Rather than constantly popping in and out of the volume mixer to make sure the audio levels are good, it can be much nicer to have some sort of hardware control that allows you to adjust the volume on the fly.
Pitfalls of ChatMix
Of course, ChatMix does have a few shortcomings:
- Relegated to SteelSeries headsets
- No Linux support
- No app filtering rules
- Requires users to “plumb” programs to the proper virtual device
The last two points require some extra explanation: even though these virtual audio devices exist, users cannot have programs automatically routed to the correct virtual device by program name, instead requiring them to change the audio setting for each program to select the proper audio output. This can become tedious and sometimes doesn’t play nice with Windows audio settings where devices will inexplicably shuffle around for no apparent reason, resetting all of that configuration.
A Solution?
This is where we get to use our previously-attained PipeWire knowledge:
- What is a “virtual device” in the context of ChatMix?
- Loopback, where the volume can be adjusted within the loopback node, not the program
- Is there a way to control the “plumbing” of applications?
- Rewiring links in the node graph based on program
name is doable via
libpipewire
- Rewiring links in the node graph based on program
name is doable via
So, in short, would it be that difficult to write a program that does what Sonar + ChatMix does with the added bonus of supporting app rules and automatic plumbing? Probably not.
Mixologist
So, let’s think about what we might need to design such an application. First, a name (because we have priorities here). Mixologist sounds like a good name so we’ll go with that. Next, we need to figure out what this program will actually do:
- Hardware volume control
- Configurable program names
- Automatic routing of programs
Hardware volume control could be done via a complex device driver but that seriously limits who could potentially use the program. Instead, we can rely on keyboard shortcuts that trigger commands via a cli of some sort. A cli does necessitate the use of some IPC however and as a result, we will probably need to use something like an abstract socket to add that. This means that a daemon will be needed as well which will manage the socket and do the actual routing. Adding a socket also enables any program to communicate with the daemon, opening up the possibility of a GUI in the future.
This gives us the following architecture:
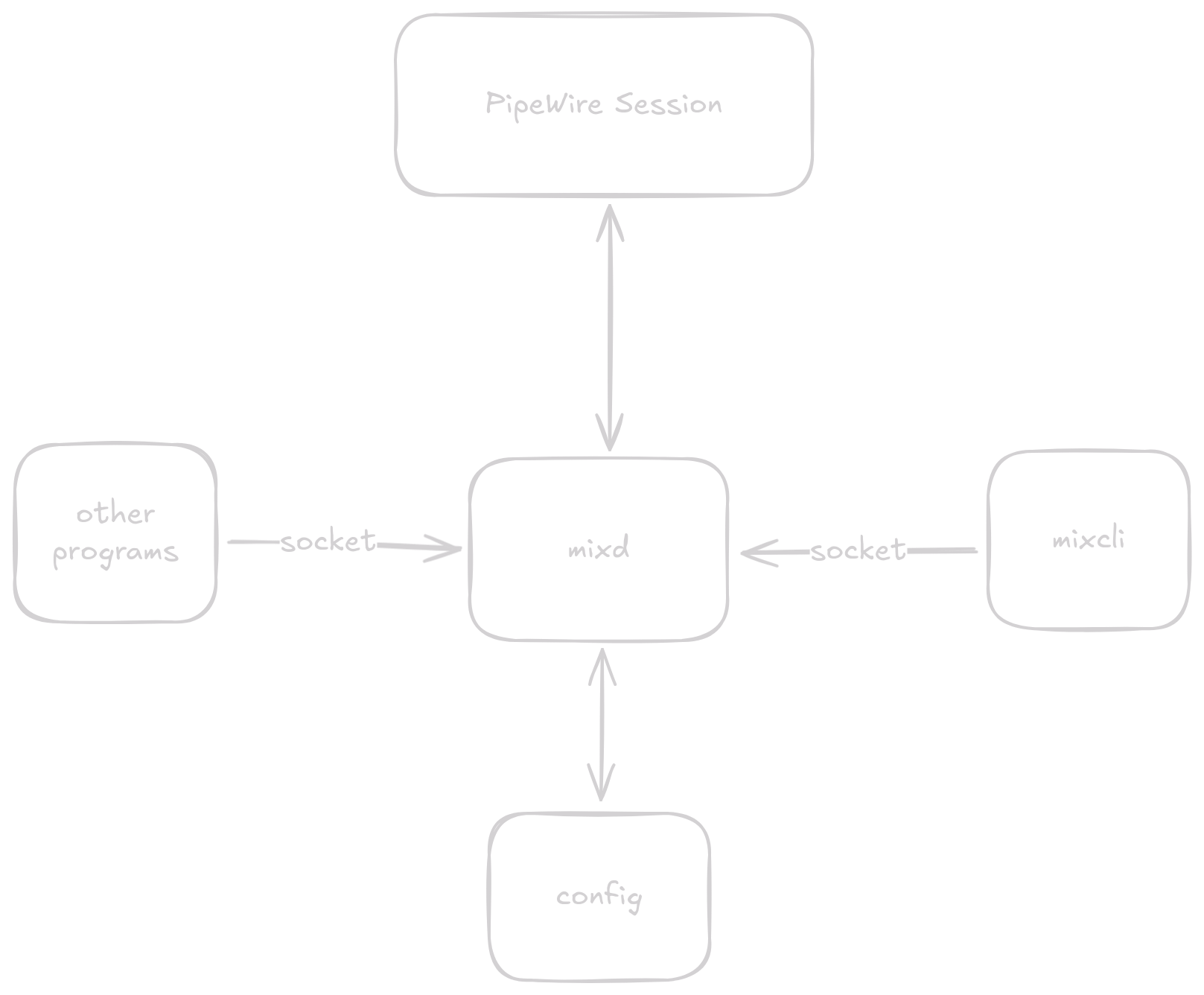
mixd
So, let’s get to the meat of the problem, the daemon.
We’ll call it mixd and think about what it should do.
- IPC
- Routing
- Volume control
- Config management
We can really contain all of the state we need for that in this struct:
| |
The first part of the struct handles the config
file itself along with hot reloading via
inotify.
The next part handles the state that PipeWire itself
requires. Note that we use a pw.thread_loop
(as opposed to the standard pw.main_loop) so
that we can still do IPC and config reloading on the
main thread. Also note the registry and registry_listener
fields, those will come in handy later.
The third section holds the meat of the application
state such as the state for each “virtual device”,
the rules to use for application routing, the volume,
and some state to handle passthrough (for things
like screen sharing). Finally, the last section just holds
data for general control flow and IPC.
Although this gives an idea of the data we keep
on-hand, this doesn’t explain how we actually do the
routing. For this, we need to prepare ourselves for
more PipeWire knowledge.
PipeWire Crash Course 2, Electric Boogaloo
The way mixd will handle PipeWire events will be
by using a registry and corresponding listener.
The registry can be thought of a global where information
about every item PipeWire knows about is stored.
Although we can (and will) query things from the registry
based on their id, the listener is much more important
to us right now.
A listener can be set up with many diffferent PipeWire objects and handlers but the handler we care about is shown below:
| |
After this setup, every time an element is
added or removed from the graph, the corresponding
procedure will get called (note the "c" calling convention):
| |
You may also notice that we register the listener with a pointer to the context struct. This is a fairly common practice with many C APIs where you also pass a data pointer to the procedure.
Fun note: Did you notice that
registry_eventsis actually attaching procedures to a struct? This is doing dynamic dispatch!
Once we enter the global_add procedure, we can do the following:
| |
This allows to to match on the different types of elements being added and handle them individually. We also then rebuild the graph after every element is added since there is no guarantee as to the order that events come in.
You might notice the
free_allat the end of the procedure. This is something that Odin allows on arena allocators (no-op on non-arenas) to free everything allocated with that allocator.
Each of these handlers do what they say on the tin
and make connections in the virtual graph that
the Context keeps around for the rebuild
procedure to then work on.
mixcli
With the majority of the daemon at least explained, we now need to turn our attention to the cli. First and foremost, we need a message passing format which can be seen here:
| |
This format is extremely simple, consisting of a tagged union with the two kinds of messages. One can either set or modulate the volume by a set value, the other can add or remove a program from the list of selected programs. This is a relatively simple message but to send it over a socket, we need to first serialize it. My format of choice will be CBOR which bears similarities to JSON while being binary encoded. This also makes reading and writing the data as simple as:
| |
CBOR is also in Odin’s
corelibrary meaning that you can use it without installing anything extra. In fact, no external libraries have been needed for either the cli or daemon.
Now that we can send messages, the rest of mixcli
is just a simple cli (which is made extremely easy
with Odin’s "core:flags" library).
Flags:
-add_program:<string>, multiple | name of program to add to aux
-remove_program:<string>, multiple | name of program to remove from aux
-set_volume:<f32> | volume to assign nodes
-shift_volume:<f32> | volume to increment nodes
End Result
So where does all of this work put us? Well, the
project can be found on GitHub
and is something I run on my personal machine.
Keyboard control can be set up in the keybinds
section of any major desktop environment.
Configuration is relatively simple, right now
being a newline separated list in
~/.config/mixologist/mixologist.conf. Hot
reloading ensures that users can also modify
the config file directly to update the program
list. Some work additionally was put into
creating a Systemd unit
to start the program on login and an RPM package
to make installing on RPM distributions simple.
Next Steps
What’s left then?
- A GUI that allows users to configure rules without having to touch the config file.
- A physical peripheral that will act as a keyboard and allow for volume mixing.
- A refactor to make the daemon something that can be embedded into any application, opening up the potential for a Flatpak.
To anyone who made it this far, thank you so much for reading!